

自社で作成したツール「機種依存文字チェッカー&変換ツール」の紹介です。
テキストの中に,丸数字(①,②など)や単位文字(㎜,㎡など)やカッコ文字(㈱,㈲など)などのいわゆる「機種依存文字」もしくは「環境依存文字」と呼ばれている文字が入っているかどうかをチェックし,「通常の文字」に変換するツールです。
いわゆる機種依存文字以外にも半角カタカナや康熙部首・CJK部首補助・CJK互換漢字と呼ばれる文字にも対応しています。
このブログではツールの紹介と共に,このツールが必要な理由について流れを追って解説しています。
大きく2つの理由があります。機種依存文字の存在と、康熙部首などの特殊文字の存在です。
目次
本ツールが必要な理由その1:機種依存文字の存在
まず、文字はコンピュータ上でどのように扱われているのか、ということから説明していきます。文字コードという考え方の大まかな流れを説明していきます。
文字コードについて
コンピュータの基本概念として 0 or 1 で情報を管理する考え方があります。
情報量を●MB(メガバイト)などと表すことがありますが、1バイトは 0 or 1 の箱が8つ集まった単位となります。
それで、1バイトで表すことができる表現の種類は、2の8乗で、256種類となります。つまり、1バイトで最大256種類の文字を表現することができることになります。
例えば、ASCII(アスキー)コードは 1バイト文字(シングルバイト文字)ですが、0~127(16進数で表現すると 0~7F)の範囲で文字を割り当てています。ASCIIコードでは、「A」は「41」、「B」は「42」という風に表します(16進数)。
英語だと、アルファベットは 26種類しかありませんので、「カンマ」や「ピリオド」、「クエスチョンマーク」などの記号を入れても、1バイトで十分表現できるわけです。
しかし、世の中にはアルファベットを使う国だけではありません。
日本語もひらがな、カタカナに加えてたくさんの漢字を使っています。ちなみに、小学校6年間で1,000字以上の漢字を勉強するようです。
それで、日本で使う文字を表現するためには、どう考えても 1バイトでは足りない!ということが分かります。
そこでマルチバイト文字が必要になってきます。
マルチバイト文字
マルチバイト文字は、その名の通り複数のバイトを用いて表現する文字です。
先ほど考えたように 1バイトで最大256字表せるので、2バイト分使えば 256 × 256 = 65,536字を表すことができます。
これだけあれば、差し当たって日常的に使う文字は表すことができます。
それで、コンピュータが日本に導入された当初、2バイトを使って文字を表していこう、という風に考えて出来たのが Shift_JIS(シフトジス)コードです。
Shift_JISコードでは、「あ」は「82A0」、「い」は「82A2」という風に表します(16進数)。
さきほどのシングルバイト文字の時と比べて、1文字を表現するのに 2倍の領域を使っている、ということがお分かりいただけると思います。
ASCIIコードと同じですね。半角文字ではわざわざ2バイト分使わなくて済むようにASCIIと互換性を持つようにうまく構成されているのです。
ちなみに,「株式会社BRISK」なら「8A90」「8EAE」「89EF」「8ED0」「42」「52」「49」「53」「4B」となります。
さて、これで6万字ほどの文字を表現できるようになりました。
とはいえやはり限りあるスペースですので,日本でこの6万ほどあるスペースにどの文字を割り当てるのかを決める際に、普段使わないようなものも全て最初から割り当てる,ということはせずに,ベースとしてよく使う文字を割り当てて、他のスペースは「空き」にしておいて『自由に』設定できるようにしました。
良い方法のように思いますが,実はこれによって機種依存文字(環境依存文字)が生み出されることになります!
機種依存文字とは?
実際の導入時に,Shift_JIS にある『自由に』設定できるスペースに、OS開発各社・メーカー各社が違う文字を入れてしまった、というわけです。
例えば、「8740」というスペースに、Windowsは「①」を、Macは「㈰」を設定しました(Macでは「①」を「8540」に割り当てています)。
このように各社が、本当に『自由に』設定してしまったことにより、書いた文字が相手に正しく見えるかどうかが「機種(環境)」に依存するようになってしまったのです。
こういう文字を機種依存文字(環境依存文字)と呼びます。
しかし、今このブログを見ている方のほとんどは、WindowsでもMacでもAndroidでも、「①」を丸数字の1 として見えているのではないでしょうか。
それは、このブログの文字コードが Shift_JIS ではなく、Unicode(UTF-8) だからです。
Unicode(ユニコード)・UTF-8とは?
Unicode は文字コードの1つです。
上記で、2バイト使えば65,536種類の文字を表すことができる、ということを記載しました。
6万字も扱えれば十分な気もしますが、実際にはそんなことはありません。
漢字だけでもその種類は5万とも8万とも言われています。(日常的に使うかどうかは別の話ですが)
日本で刊行されている 『大漢和辞典』(大修館書店)には約5万字が収録されていますし、中国で出版されている『漢語大字典』(四川辞書出版社・湖北辞書出版社刊行)には約6万字、『中華字海』(中華書局)には、なんと8万字以上も収められているそうです。
引用元:この世に漢字はいくつありますか – ことばの疑問 – ことば研究館
そして、世の中の文字はアルファベットと漢字だけではありません。
韓国語(안녕하세요)やタイ語(สวัสดี)、アラビア語(مرحبًا)など、言語の数だけ文字の種類があります。(← すべて「こんにちは」を意味する言葉です)
つまり、世の中のすべての文字を表そうと思うと 2バイトでは全然足りない、ということが分かります。
それで、すべての文字を表現することができる仕組み(規格)が考え出されました。
いわば世界統一文字コード、それが Unicode です。
▼What is Unicode?
The Unicode Standard refers to the standard character set that represents all natural language characters. Unicode can encode up to roughly 1.1 million characters, allowing it to support all of the world’s languages and scripts in a single, universal standard.
– Google翻訳 –
▼ユニコードとは何ですか?
Unicode 標準は、すべての自然言語文字を表す標準文字セットを指します。Unicode は最大約 110 万文字をエンコードできるため、世界中のすべての言語と文字を単一の普遍的な標準でサポートできます。
引用元:Technical Quick Start Guide – Unicode▼How Did Unicode Get its Name?
・universal (addressing the needs of world languages)
・uniform (fixed-width codes for efficient access), and
・unique (bit sequence has only one interpretation into character codes)
– Google翻訳 –
▼Unicode という名前はどのようにして付けられたのでしょうか?
・ユニバーサル(世界の言語のニーズに対応)
・均一 (効率的なアクセスのための固定幅コード)、および
・ユニーク (ビットシーケンスの文字コードへの解釈は 1 つだけです)
引用元:About Unicode – Unicode
Unicodeの策定には多くの組織が関わっており、たくさんの協議を経てどのコードにどの文字を割り当てるかが決定されています。
Unicodeのサイトを見ると分かりますが、絵文字もどんどんと追加されていっています。
このUnicodeを用いることにより、機種によって見え方が変わる、ということが無くなりました。
言い方を変えると、Unicodeを用いる限り「機種依存文字」「環境依存文字」というものは存在しない、ということになります!!
そして最近のウェブサイトはほとんど Unicode(UTF-8)で作られているため、どの環境からでも同じ文字が見えるようになっています。
W3Techsのサイトによると、2023年7月現在では、98%のウェブサイトがUTF-8で作成されているようです。

それで、現在ウェブサイトにおいては文字化けするのはかなりレアなサイト、ということになります。
メールでのエンコード
では、現在は機種依存文字のことは全く考慮せずにどんな文字でも使ってOK、ということでしょうか。
そういうわけでもなく、メールの送信の際に一般的に用いられる文字コード ISO-2022-JP はJISコード準拠のためUnicodeで設定されている文字が設定されていないケースがあります(GmailではUTF-8を採用しているためGmail同士で直接メールするようなケースは大丈夫ですが、相手のメールプロバイダの種類やシステムから送信されるメールの場合は文字化けする可能性があります)。
具体的に言うと「①」や「㈱」など、いわゆる「機種依存文字」は設定されていません。
ウェブサイトのみの場合はUnicodeのおかげで機種依存文字が無くなったと思いきや、メール送信の際に文字化けしてしまうことがあるため、やはりもう少し「機種依存文字」と付き合っていく必要があります。
最初の導入部に「半角カタカナ」について触れていますが、半角カタカナは「機種依存文字」ではありません。Shift_JISで立派に定義されています。
しかし、メールで一般的に使われる「ISO-2022-JP」では定義されていないのです。これが半角カタカナを避けた方が良いと言われる大きな理由の1つです。
それで、メールのことを全く考えないのであれば半角カタカナを使っても表示に関しては問題は生じません。(個人的には半角カタカナが混じっていると気になりますが)
小まとめ
それで、98%のウェブサイトがUTF-8で作られている時代ではありますが、できれば機種依存文字が入り込まないようにするのが良いのかもしれません。
特にCMSと連携してメルマガ配信などをする場合にはそう言えます。
ウェブ上でのみ扱う場合は特に問題なく使用できますが、ユーザーがそれをコピペしてShift_JISのエディタやシステムで扱う際には問題が発生することがあるかもしれません。
機種依存文字が含まれている原稿から自動で『機種依存しない文字』に変換したいときには、「機種依存文字チェッカー&変換ツール」をどうぞお試しください。
本ツールが必要な理由その2:康熙部首などの特殊文字の存在
Shift_JISを使わずに Unicode だけで表現する場合であってもまだ別の問題が発生する可能性があります。
その問題を引き起こすのが康熙部首などの特殊文字の存在です。
康熙部首とは?
康熙部首(こうきぶしゅ)という種類の文字をご存じでしょうか。
部首や旁(つくり)の部分を1文字として表すための文字で,「⼥」(おんなへん)「⽇」(ひへん)「⽷」(いとへん)などがあります。
この康熙部首の厄介なところは,通常の漢字「女」(おんな)「日」(ひ)「糸」(いと)と文字コードとしては別なのに見た目が全く同じになってしまうということです(見た目が違ったり表示できないフォントもありますが)。
試しに上記の部分をコピーして,メモ帳やテキストエディタに貼り付けてみると違いが分かると思います。
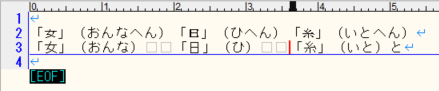
テキストエディタ
見た目が同じでも文字コードが違うので(つまり実質は違う文字なので)、検索の際にうまく検索できなかったり、テキスト読み上げが正しく行われなかったりします。
康熙部首などの特殊文字にテキストリーダー側がまだ対応できていない、という面もありますので、アクセシビリティのことを考えたサイト作りにおいては出来るだけ使わない方がよいでしょう。使う必要がある場合にはカッコ書きで説明を書いておくことができます。(例:草彅(なぎ)など)
ChromeやEdgeの検索機能を使えば、「⼥」(おんなへん)も「女」(おんな)もうまく検索できます。スゴイですね。
FireFoxは検索出来ませんでした。検索の際の文字コードについてのポリシーが違うのでしょう。
見た目が一緒とはいえ実際には違う文字なので検索させるかどうかはどちらも間違いではない気がします。
ちなみに、ChromeやEdgeで、「1」で検索すると「1」「1」「①」「❶」などもすべてヒットします。人間的な観点での表記ゆれに対応した検索、と言えるでしょう。
CJK部首補助とは?
CJK部首補助も康熙部首と同じく、部首を表す文字(表現)と考えていただければ大丈夫です。
「⺖」や「⺇」などがあります。
ちなみに、CJKとは Chinese, Japanese, Koreanの頭文字です。東アジアで使われている文字をまとめて指すための表現のようです。
CJK互換漢字とは?
CJK互換漢字に含まれている文字にはいろいろな経緯がありますが、以下のようなものがあります。人名で使われる通常の漢字と少し違っている文字(異体字と呼ばれる文字)も含まれています。
韓国や北朝鮮、台湾の規格で、日本語の漢字とは違う発音だが見た目が日本語と全く同じもの
例:更、句、落など。 日本語では更、句、落。
以前は通常の文字ではなく拡張文字として扱っていた漢字
例:塚、﨑、神など。 通常では塚、崎、神。
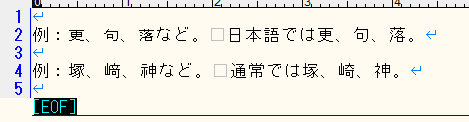
テキストエディタ
どんな時に使われるの?
ここまでの説明で、「山﨑」などの人名では使うこともあるだろうけど、そもそも「康熙部首」って言葉も初めて聞いたし、その文字を使うケースなんてあるの?と思われるかもしれません。
通常わたしたち日本人が文章を書くケースで康熙部首が紛れ込むことはほぼありません。
しかし、書いた文章をPDFやその他のフォーマットに変換してそれを読み込んだりした場合、康熙部首が紛れ込むことがあるようです。
ウェブ制作をしていて、クライアントからテキストをもらう場合に稀に遭遇することがあります。
UTF-8では問題なく表示されて見た目もほとんど同じなので、気付かずにそのままウェブサイトにそのテキストを使ってしまうことがあるわけです。
小まとめ
見た目は問題なくても、検索やテキスト読み上げ時に想定通りの動作をしない、ということがありますので、康熙部首やCJK部首補助は必ず省いた方が良いでしょう。自分の意図とは違う字を使ってしまっている、ということですから。
またメールで文字化けする現象は、機種依存文字と同じく康熙部首などの特殊文字でも発生するケースがありますので、出来れば使わない方が良いでしょう。
康熙部首などの特殊文字が含まれている原稿から自動で『機種依存しない文字』に変換したいときには、「機種依存文字チェッカー&変換ツール」をどうぞお試しください。
機種依存文字チェッカー&変換ツールの紹介
さて、いよいよ「機種依存文字チェッカー&変換ツール」の紹介です。
以下の画像のようなツールです。
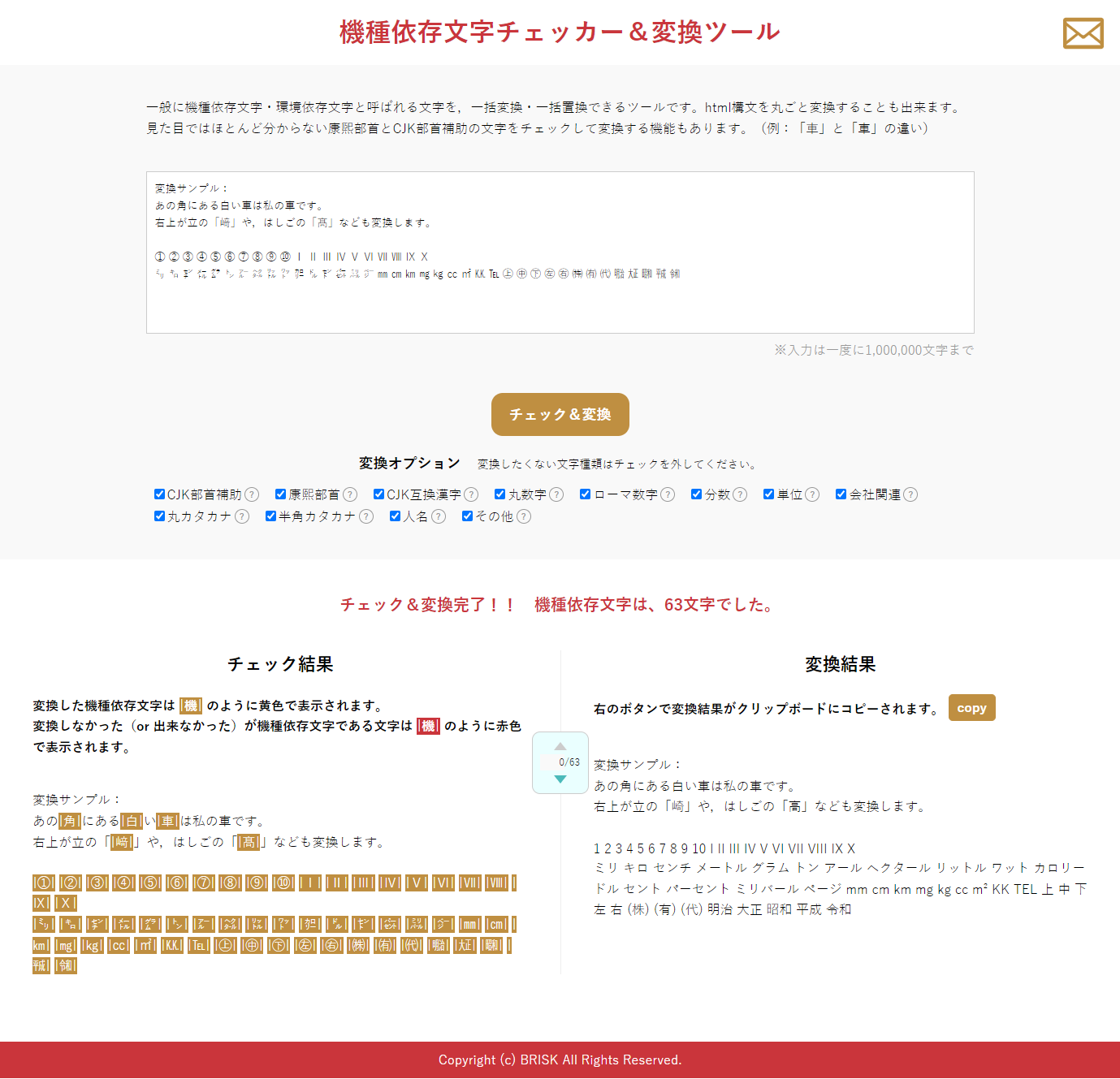
分かりやすさ重視で「機種依存文字チェッカー&変換ツール」という名前にしていますが、ここまで説明してきた康熙部首などの特殊文字などの「機種依存文字」以外にも対応しています。
チェックするだけではなく変換してくれると良いなぁ、と思っていましたのでチェック結果と変換結果を横並びにしています。
また、変換処理は未実装の文字もありますのでそういう文字があった場合には、チェック側で色を変えて表示するようにしています。
さらにhtml構文を丸ごと入れたいニーズもあるかもしれませんので、その場合も問題なく動くようにしています。
100万字を一度に処理できます(文字数が多いと少し処理に時間がかかりますが)。
チェックされた文字には色を付けてはいますが、長いテキストの場合には、どこにその文字があったかを目視で確認するのも大変なので、中央にナビゲーションも実装しています。
変換処理は、オプションでどの種類を変換しないか、ということも選択できるようにしています。
まだまだ変換する文字は追加予定ですが、この文字をこう変換して欲しい、というご要望などありましたらContactからお知らせください。
まとめ
ウェブの世界は日進月歩です。10年前にはShift_JISのサイトもそこそこ存在しましたが、2023年現在では98%がUTF-8で作られている、というのはわたしも嬉しい驚きでした。
ウェブサイト以外でも様々なソフトやツールがありますので、機種依存文字や康熙部首などの特殊文字を全く気にしなくて良くなるのはもう少し先の将来でしょうね。
アクセシビリティの高いサイトを制作するニーズも高まってきているため、テキスト読み上げツールのことも考慮する必要があるため、「見えたらよい」というわけではない世の中にもなってきています。
でも、Unicodeの目指す通り、全ての環境で何も気にせず入力することができるようになれば良いですね!
それまでの間はいましばらく「機種依存文字チェッカー&変換ツール」などを使って対応していきましょう。
南本貴之






のブロックエディター Gutenberg(グーテンベルク)の使い方")
